













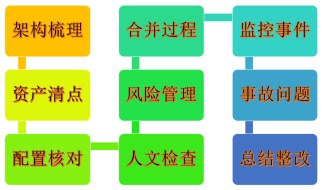
【51CTO.com原创稿件】在上一期讨论中,我们针对双方企业待合并的现有架构、资产、配置、以及人文等方面,进行了“地毯式”的检查与比对。不过按照管理学领域的所谓“10倍思维”,如果我们把事情做得10倍的完善,实际上要比做到它的10%,更加容易达成。那么,下面我们来看看,是否还有哪些地方仍然值得我们去深耕与细作?
【廉环话】不要让数据安全成为“盲盒”里的那只猫 -- 浅谈咨询业数据安全体系建设
【廉环话】防疫一周年后的IT治理思考 --可用性、关系与财务管理
【廉环话】防疫一周年后的IT治理思考 --能力、知识、问题与请求管理
【廉环话】防疫一周年后的IT项目管理思考 -- 设计、开发、安全
【廉环话】防疫一周年后的IT项目管理思考 --测试、部署、发布
【廉环话】防疫一周年后的IT项目管理思考 --验收、监控、改进、变更
【廉环话】防疫一周年后IT变革的思考--架构、资产、配置、人文
风险管理
首先从风险类型上说,IT系统的合并项目往往会面临如下风险:
- 时间风险:企业合并虽然是一个渐进过程,但是IT系统的转换往往会有一个设定期限。一旦超期,双方企业可能蒙受巨大的经济损失。
- 成本风险:显然,如果IT系统合并的成本过高,会有悖于企业当下“抱团取暖”的初衷。
- 范围风险:如果前期功课未做到位,很可能出现真实的系统与环境,远比想象的要更大、更复杂。
- 技术风险:在系统整合或迁移过程中,所涉及到的新技术,超过了IT团队的驾驭能力,导致他们无法迅速上手。
- 法律风险:由于原有合同具有排他性,导致目标系统被修改或整合后,失去了许可证的有效性或相应的技术支持。当然,我们也可能会碰到对方系统尚未完成合规性认证等情况。
那么,基于上述风险,我们需要实现什么样的管控目标呢?针对企业当前的合并阶段,我们需要重视与实现如下五个目标:
- 保持并促进企业业务的可持续开展与发展。
- 保证企业系统与服务的可持续交付与提供。
- 保障企业后续的运维所需数据与信息的完整性和准确性。
- 确保企业后续的运营符合相关法律、法规、以及合同义务。
- 实现企业软、硬件资产与资源的有效供给与传承。
有了目标,我们在具体实施环境中,就可以借用业界常提到的SMART原则,来着手识别和管控风险了。
- S(Special),由于某一个环节可能潜在多个风险,而某一个风险又可能反过来影响多个环节,因此我们在识别风险时要具体,不可笼统。
- M(Measurable),我们要识别风险,更要了解风险的危害程度,因此我们需要采用下面将提到的定量和定性两个方法,让风险指标更加明确可信。
- A(Attainable),我们在根据风险制定与采取应对措施时,应确保管控目标和方法的切实可行,尽量做到“踮起脚尖就可够到”。
- R(Relevant),我们需要根据真实环境来识别风险。一些业界常见的风险点,可能并不适用或不一定会在系统并购的过程中出现,因此需要有针对性和相关性。
- T(Time-bound),显然,并购开始的日期便是那只即将落下来的“靴子”。我们需要通过倒推时间,以确定风险管控各个步骤的时间节点。
根据上述五项原则,我们便可以通过如下通用流程,来开展风险管控了:
- 计划:根据IT系统的整体特点,参照时间表、预算和范围,提出风险管理的目标、实施的人员、以及执行的方法。
- 识别:可采用如下经典的方法,来识别现有系统与环境在整合过程中,可能面临的风险特征。
- 财务报表分析法,通过现有的资产负债表、损益表、现金流量表等财务信息,根据业界经验,通过数学模型来进行识别。
- 流程图表分析法,通过审查当前业务与系统的处理流程,分解矩阵与图表,找到关键环节、薄弱环节、以及实施过程中的风险点。
- 事件与故障树分析法,通过重审过往的事故记录与文档,顺藤摸瓜地对根本原因进行重新分析与评估。
- 现场走查分析法,召集相关人员来到系统所在地,通过互动访谈、设备状态检查、表格填写等方式,集思广益地发现各种潜在隐患。
- 保单对照法,通过参照保险公司提供的保单里的风险条目,以及过往的出险记录,识别和界定各类风险事项。
- 分析:根据前面收集到的数据与特征,运用数字定量和程度定性等不同方法,对已发现的风险进行评估与排序,得出具体数值,或是区分高、中、低风险等级的矩阵。具体可以参照如下两个维度:
- 可能性,例如:我们可以通过检查过往事件/事故的记录、系统所处的物理与逻辑区域、本身的容错能力、以及等级保护与合规的达标情况,得出:很少、不太可能、可能、很可能、几乎确定,这五种等级。
- 影响范围,例如:根据是会影响到整个组织、所有外部客户、还是会涉及到多个站点、某个部门、亦或部分系统与服务等方面,得出:不重要、次要、中等、主要、灾难性,这五个量级。
- 应对:采用通用的风险减轻、转移、规避、以及接受,这四种方法,既减少合并中故障的发现,又能够为必要时的全面复盘做好基础性的准备。同时,我们应根据木桶原理,注意措施的一致性,以免出现局部“短板”。
- 整改:在后续完成系统整合后,我们需要通过下面将要会讨论到的持续监控与事故跟踪,既能够识别新的风险,又可以控制残留风险的态势,进而提出进一步的整改计划。
我们常说:安全性是系统风险的主要来源。不过,在系统合并这一特定场景中,我认为:相对于受到外部攻击所导致的机密性被破坏,数据的完整性与IT服务系统的可用性,才是我们需要在此阶段全面防范的安全风险。同时,由于风险的责任所有者(通常是业务方)和管控实践者(通常是IT与安全人员)并非同一角色,因此那些与安全相关的问题,往往会叠加风险的不确定性。这也是我们需要通过持续的监控和详尽的文档,来体现尽职免责的原因。毕竟,企业合并是一个双方协作的过程,不要最终变成了只是买了对方的“遗迹”。
合并过程
正所谓“不同的师傅有不同解题思路”,我们且不谈在技术上各家针对系统合并的独门秘籍。下面让我们主要关注在合并过程中,特别是首日(Day One),应当做好哪些管控工作。
- 为了应对系统切换与合并后可能发生的爆发性问题,我们可以采用“双活”的战略,即:通过签署诸如过渡服务协议(Transition Services Agreements)等来进行缓冲,以确保在合并之后的一段时间内,双方内、外部用户能够按需临时切换至原有的系统,完成关键业务。
- 当然,我们也可以临时租用云服务与空间,来提供合并期的不间断过渡服务,直至新的系统能够稳定地运行,并提供服务。
- 面对用户与客户碰到的问题可能会出现雪崩式的增长,以及服务台与呼叫中心在工作量上的激增,我们应提前准备好通知模板与自动响应机制,并分配足够的现场支持人员,以汇总与处置各种突发问题。
- 从业务安全的角度上说,某些IT服务与应用的使用者、以及支持管理人员可能会在合并之后发生变动。对此,我们需要通过集中式的细粒度控制方法、予以重新分配角色和授权,以降低人员转岗所带来的权限积累与残留等安全隐患与风险。
- 在完成合并后,如果某些设备不再被延续使用,那么就应当通过指派专门的设备管理员,遵从如下不同的处置方式,通过带有详实记录的操作流程,及时清理设备介质中的残留数据,以免产生信息泄漏:

监控事件
在时间和操作上完成了IT系统的合并后,我们需要迅速建立和完善原有的主动监控和响应机制,最小化或消除新的系统状态对于业务发展的负面影响。通常,我们需要从系统、网络与应用三个方面,开展持续的监控活动。鉴于双方IT系统往往在合并前,就已经具备了一定的服务监控与事件响应水平,我们在此阶段主要关注的是:根据实际情况,对被监控的配置项(CI)、参照的基准、以及门限阀值的设定,进行重新评估与审查,以有效地实现事件的分类、分级,并剔除误报。
值得一提的是,为了避免双方团队对于事件的理解和界定存在分歧,我们可以参照如下定义,针对在监控过程中捕捉到的事件信息,按照其重要程度进行的区分:
- 信息性事件,不需要采取行动,但值得收集和后期分析。例如:A企业的客户数据已完成了向B企业物流派送系统的导入,并产生了事件记录。
- 警告,在业务实际发生负面影响之前,产生的有待采取行动的信息。例如:A企业的Web服务器在承接了B企业的业务量后,CPU的使用率接近设定阈值,系统临近预设的稳定性拐点。
- 异常,确实违反了既定的规范,即使未显著影响业务,也要采取措施。例如:上述Web服务器的CPU使用率已经超过了阈值,需要立即给虚拟机增加CPU算力。
由于上述各类事件往往是从自动化监控工具中捕获而来,因此我们需要对事件实施:自动分配编号,初步判断类型,过滤重复与无效,根据标准分级,准确读取和分派给恰当的IT角色,按需实现多部门联动,以及自动关联处理路径与措施等。
总的说来,我们可以参考如下流程,对合并后的突发事件进行管控。当然,为了集中精力做好系统合并,我们也可以通过合同,委托给提供监控服务的第三方,使其将过滤后的事件及时转发给企业的运维团队。
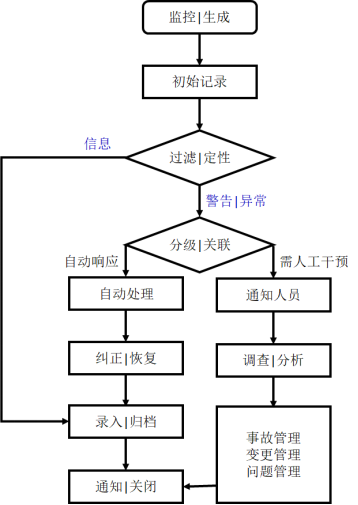
事故问题
既然系统的合并过程存在着许多不定因素,那么我们难免会碰到各种后续事故与问题。那么,为了最小化负面影响,尽快恢复业务服务,以及重拾内、外部用户的满意度,我们需要通过如下流程,在期望的时间内,通过变更等手段予以解决。
- 前期准备:我们需要针对合并后保留、融合、以及新建的服务与系统,开展或重审业务影响分析(BIA),推算并确认最大允许中断时间(MTD)。
- 根据能够获取到的资源(毕竟在企业合并后的一段时间内,某些资源不一定能够持续提供),以及需要参照的业界规定与标准,对可能发生的中断和事故,重审风险管控阶段制定好的定义、分类与分级。
- 审查或制定新的紧急联系人列表、业务单元优先级列表、事故原始记录表、事故危害矩阵图、以及具体的应急响应计划。当然,这些表格与报告模板都需要被呈交到了各个业务相关部门,根据他们的反馈意见进行及时的调整,并最终获取管理层的批准。
- 调查与分析:面对用户反馈来的、带有主观判断的报告,以及自动化监控平台推送来的海量信息,新组建的响应团队需要在剔除误报的基础上,从数量与程度两个维度进行分析。当然,他们也会按需通过深入调查与跟踪,来对一些滞后或间接的影响予以评估。
- 报告与公关:为了有效地管理突发事故所造成的危机,该团队需要:
- 根据联系人列表,以邮件、电话、微信、甚至是广播的形式,告知可能波及到的内部相关人员。
- 按照“快报事实、慎报原因”的原则,按需向客户、合作方、以及外部监管部门提供事故的情况说明、以及必要的技术细节问答。
- 抑制与补救:在针对事故的抑制、恢复、以及根除过程中,响应团队需要按照既定的优先级,予以恢复或采取变通的办法。当然,各个职能角色之间的沟通与协调,也是非常必要的。
总结整改
在合并的最终阶段,我们需要回顾IT系统在各个环节的实际执行情况,对于风险和事故管控的效果,提出建设性的意见与实施方案,并协同新的相关部门进行改进。与此同时,对于那些暂时无法找到有效解决方案的问题,我们则需要记录到已知错误数据库中,以减少将来复发的频率和影响。
当然,除了总结系统与流程,IT管理层也应当在保证团队成员基本利益的前提下,重新定义他们的工作职能与范围;在降低人员流动率的同时,适当采取“末位淘汰制”,以壮士断腕的决心提高整体战斗力。
结语
总的说来,IT系统的合并既像是一次阅兵演习,又像是一场闪电战。我们只有做好了充分的“军备”,才能面对严苛的时间节点,有条不紊地完成任务。正如下图所示,我们实际上可以将整体推进的流程,绘制在会议室的白板上,向整个团队传递“破案”的即视感、责任感与紧迫感。
当然,上述环节与要点其实都是我根据自己在本企业经历,进行的一些思考与总结。它们既可能挂一漏万,也可能只是所谓的“幸存者偏差”。不过,正所谓:聊胜于无,真心希望大家能够从中收获点滴,习得善于“打群架”,打好“群架”的本领。
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】





