













【51CTO.com原创稿件】大家好,截至上期,我们已经在实质上将手头的IT项目发布出去了。但是,正如那些得以敲钟上市的公司往往担心会“破发”那样,我们也不希望自己好不容易完成的项目迅速成为了“月抛型”。为此,我们需要在服务系统发布之后,对其开展各项后期“保值”工作。
本系列文章如下:
【廉环话】不要让数据安全成为“盲盒”里的那只猫 -- 浅谈咨询业数据安全体系建设
【廉环话】防疫一周年后的IT治理思考 --可用性、关系与财务管理
【廉环话】防疫一周年后的IT治理思考 --能力、知识、问题与请求管理
【廉环话】防疫一周年后的IT项目管理思考 -- 设计、开发、安全
【廉环话】防疫一周年后的IT项目管理思考 --测试、部署、发布
验收确认
既然服务产品已经能够以一套正确的、被授权的、以及经过内部测试的软/硬件形式存在于实际生产环境中,那么我们就需要协同需求方、以及使用方,顺势开展项目的验收与确认工作。通常,我们可以将验收分为初验和终验两个阶段:
- 初验,一般发生在系统部署完成之时,主要着眼于服务功能方面。那些在初验中发现的问题,应当以书面备忘录的形式被记录,由服务的开发方承诺解决的时限,并由验收双方签字予以确认和归档。
- 终验,一般发生在系统完成发布、并已试运行一段时间之后,主要关注的是服务性能方面。我们既可以从实际使用方收集反馈意见,也可以邀请有资质的第三方予以评测与验收。
在完成初验与终验工作后,我们需要及时更新配置项数据库(CMDB)里的相关配置项(CI),以及已知错误知识库(KEDB)里的信息。通过运用易于使用方理解的语言,去描述错误的现象与特征,我们不但可以提前向用户传递和警示可能碰到的问题,还能够合理地控制他们在使用过程中的期望值和体验度。此外,提供相应的技术支持和用户培训,也是在服务发布后和验收确认前阶段,所必不可少的环节。
监控分析
新增的服务在被使用一段时间后,往往会出现加载时间、交付效率、以及运行性能等方面的变化;而那些变更的服务则可能逐渐对原有的系统产生流量、负载、出错了等方面的影响。为此,我们需要通过针对关键性衡量指标的监控,及时捕获和评估出流量的峰值、负载的瓶颈、甚至是逻辑上的调用错误。
显然,为了量化目标系统与服务的各方面表现,在着手进行相关指标的挖掘和分类之前,我们需要先确定待采集的关键点指标(也就是我们常说的“绘制仪表盘”),然后才能将这些关键点的表现状况与期望值进行比较。下面是针对常规系统与服务的两大类监控指标,以及参考依据:
- 资源指标
- CPU使用率:是指进程使用CPU的时间百分比。通常,我们可以接受的使用率为85%以下。也就是说,如果CPU的空闲持续为0,或者运行的队列数远大于CPU的核数,则被视为CPU 出现了瓶颈。
- 内存利用率:如果空闲的内存过小,会出现系统频繁地调动磁盘页面文件的情况。因此通常我们应保证至少有10%可用的内存。也就是说,内存的使用率也不应达到或超过90%。
- 磁盘I/O:其中,写I/O操作是指将数据存入磁盘,读I/O操作则是指从磁盘读取数据。我们可以采用不同操作所占用的时间百分比来度量。当每个磁盘的I/O数超过其本身标注的I/O能力时,则会导致CPU的等待。也就是说,当磁盘需要长时间进行大数据量的读写操作时,就会产生磁盘I/O的瓶颈。
- 网络带宽:我们可以通过计算目标系统每秒发送和接收字节的速率,来和现有网络资源所承诺的速率作比较。例如,我们可以尝试性地减少网络出口处交换设备所提供的转发能力,来检查下列性能指标的受影响程度。
- 性能指标
- 并发用户数:是在某个抽样时刻,同时向系统提交请求或接受数据的用户数。
- 在线用户数:是在某个时间段内,访问目标系统的用户总数。毕竟并非所有访问用户,都在同时与系统进行数据交换。也就是说,只要其会话处于活跃状态,即可算作在线用户。
- 平均响应时间:是指从用户提交访问请求,到其接收到系统响应所消耗的平均时间。随着软/硬件技术的发展,如今我们对于平均响应时间的期望往往要求在3秒之内。
- 事务成功率:是指在单位时间内,系统能够成功完成诸如:用户登录、提交订单、完成支付等操作(即,既定事务)的数量,占总体事务的比例。
- 超时错误率:是指那些由于超时或各种错误所导致的失败事务的占比。例如,页面上产生的HTTP 4XX和5XX等错误,以及由于线程中止所导致的应用重启等故障。
综上,我们需要监控的各项基本指标,可被归纳到下图之中。当然,您也可以根据实际情况对其进行增减。
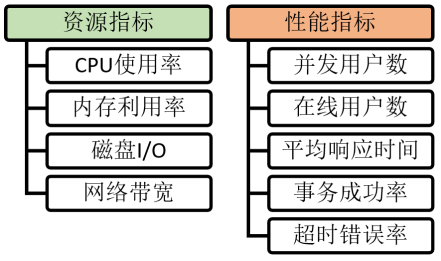
就监控的频率而言,我们可以按天计、甚至按小时来采集。而评估的周期则一般可以按照每月或每季度为单位进行考核分析。当然,在实际应用中,上述各方面的指标会存在着互相依赖、或相互影响的关系,我们往往不能孤立地只从某个切面去排查与分析。这也就是为何我们需要用全面的报告,配上综合图表的形式呈现出,系统的当前状态与设计目标之间的差距,再利用上下文的关联分析,以及趋势判断,来顺藤摸瓜地找到瓶颈的症结,以便在下一个环节着手改进。
值得一提的是,随着企业对于云服务的使用和对于业务连续性的重视,项目运维团队应当花费更多的时间从RTO和RPO出发,去重点评估不同用户终端的可访问性、服务的高可用性、不同地域的响应时间、以及存储的频率和备份的深度等指标。据此,我们不但可以合理地按需分配和调整服务相关资源,还能够通过与云服务商的协作,来提高系统的服务水平与鲁棒性。
持续改进
各种由使用方回馈来的缺陷、或是由运维人员通过监控环节发现的问题,最终都需要被转呈服务开发团队进行改进。通常,我们可以分为:被动式紧急整改和主动式稳健改进,这么两种方式。
对于被动式紧急整改而言,由于时间紧、任务急,我们需要注意如下两个方面:
- 圈定范围:由于当前系统服务往往存在着功能繁杂、代码量大、依赖关系错综等特点,会导致整改起来难度较大,且成本较高。因此,我们的首要任务是要缩小、明确待整改的具体范围。在实践中,如果能选择的话,我们可以从一些功能性单一、且非关键性的组件开始。
- 解耦功能与数据:为了将某些功能、及其数据从原有的系统中剥离出去,并保证持续提供既有的服务,我们可以适当地使用前端代理、或后端转发的机制,来临时构建和提供组合式系统。
虽然属于紧急整改,但是我们仍需秉承“由大到小,增量渐进,关注运营,及时调整”的构建原则,并在实现方式上适当地借鉴:通过云服务平台提高运能,引入微服务架构提高灵活性,采用模板化和自动化促进智能运维等方面。
而针对主动式稳健改进而言,随着软件技术和硬件设施的不断迭代与进步,许多企业都会通过设立技术创新委员会,来对各种有利于改进现有服务、和提高当前生产率的技术与产品予以持续关注,并伺机采用。同时,他们也应当以开放的心态,鼓励第三方与之分享和展示新的技术产品,并通过对外提供数据源与分析支持等方式,协同优化现有的服务质量与流程。
当然,在具体实操中,我们仍需要从整体性能、运营成本、以及服务产品的互操作性和延续性出发,进行“小步快跑”。特别是对于一些稳定的云端应用与业务,我们要事先做好如下两个方面的准备工作:
- 摸清现有云平台所用到的API、数据格式、标准与支持文档、业务定制部分、平台依赖性、以及与新技术可能出现的不兼容性等问题。
- 做好现有数据的备份、导出切换、顺序导入、以及详尽的回滚方案。
总之,持续改进既需要多方的协作,也需要全面的考虑。
变更控制
在完成了整改或改进措施的准备工作后,我们最后通过一套正式的变更流程,将其部署到生产环境、或替换当前的服务。由于此类变更往往会引起不同时长的中断,因此在变更请求(Request for Change,RFC)的提交准备环节,我们需要围绕着:“变更什么?何时变更?有何影响?”,这三类问题展开。据此,变更请求的具体内容通常会包括:
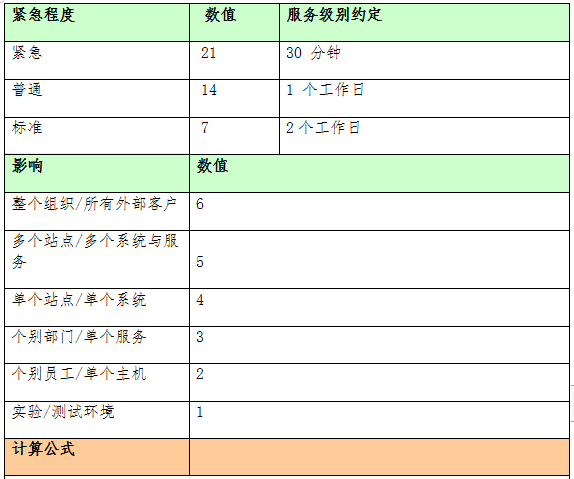
- 需求程度:属于标准、一般还是紧急。其中:
- 标准变更,是低风险、且预授权的变更,易于被理解与记录。初创此类变更时,应全面评估风险并完成授权,之后不必重复。
- 一般变更,应根据类型与既定的模型,来确定需要评估和授权的角色。可由手动创建请求,也可由CI/CD管道进行自动化加速。
- 紧急变更,包括解决事故或部署热补丁等需求。应尽可能地经历与一般变更相同的测试、评估和授权环节。在实施前,酌情允许缺少相关文件。由于时间受限,测试较少,因此需要了解业务风险的高级管理人员予以人工授权。
- 变更类型:操作系统、应用软件、硬件设备、网络组件、通信线路、文档目录、配置项、以及安全相关。
- 风险预判:低、中、高。
- 影响预判:单个应用系统、部分用户群、职能部门范围、多分支站点、整个企业。
- 变更时间:提议开始时间、目标完成时间与耗时。
- 变更内容:当前状态、更改内容、预期目标。
- 回滚计划、变更前后的测试方案等。
在具体实践中,我们还需要根据请求的不同特征与细节,注意如下方面:
- 分清变更发起人与实施人。有时候发起变更请求方不一定是真正实施的人员。
- 根据波及范围与紧急程度的不同,应事先规定好不同的颜色代码,以便审批人员能够从庞复的记录中,一眼认出或筛选出重大的变更需求;同时也能够引起相关技术人员与受影响用户的注意。
- 可以附上必要的截图、邮件或文档,让审批人员更为深入且全面地了解变更产生的来龙去脉。而且,如果涉及到比较复杂或大型的变更,我们还应适当地配上能够体现变更步骤的流程图,以提审批人员参考。
在规范的企业中,变更请求一定需要通过变更管理委员会(Change Control Board,CCB)的审查与批准。其中:
- 该委员会的成员通常包括:企业业务部门、IT管理层、技术专业职能部门、以及外包/供应商等代表。当然,除了固定的人员角色之外,也可根据实际变更请求的特点,动态进行调整。
- 审批与检查的主要内容包括:提出人员的角色、变更的合理性、预期收益、时间安排、所需资源、以及对其他产品与服务的影响等方面。
- 委员会成员之间应共享一张“事件汇总日历”,以便根据请求的时间,全盘考虑变更时段的忙闲程度,按需调整计划,并最终将其加入总日历表中。
在具体审批过程中,委员会可借助如下风险矩阵表予以评估:
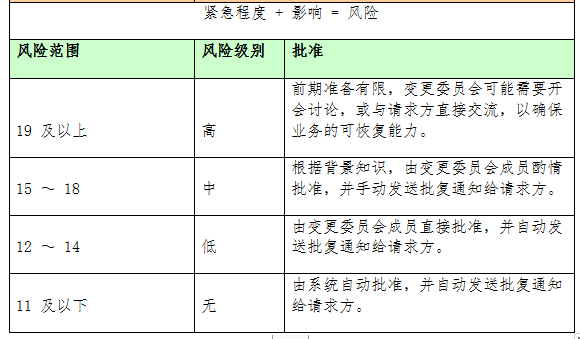
当然,为了避免频繁的变更请求打扰、甚至拖累委员会成员的日常工作,同时也为了避免重要的变更被长期积压,委员会可以分别在每周二、四的中午,进行审批例会。通过集思广益与讨论磋商,委员会最终应做出批准、还是拒绝的结论。
实施人员在开始变更之前,应完成如下三个方面:
- 在独立的系统上执行并完成基本测试与演练。
- 使用事先规定好不同颜色代码的通知模板,向相关人群发送服务中断与变更实施的相关通知。
- 为目标系统建立基准线,也就是俗称的:给系统的当前状态“拍快照”。该基线既可以作为变更后参考比对的依据,又能够成为回滚操作的目标。
而在完成变更后,实施人员既要及时更新配置项(CI),又要做好相应的文档记录,以备后期审计。
综上,我们应当遵从如下变更管理流程与推进顺序:
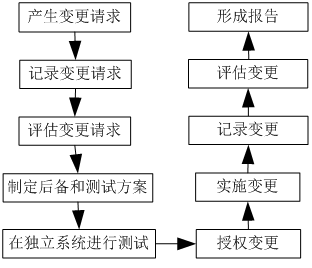
值得一提的是,那些针对虚拟化和云服务的调整,会与传统的变更有所不同之处。我们尤其应当注意如下两个方面:
- 应充分计划与记录各种对于镜像与配置模板的修改、云存储空间的配额、以及虚拟CPU/内存资源的增减等操作。
- 对于前面提到的被动式紧急整改,应当根据既定的协议,与云服务提供商事先明确好各自的职责。例如:在何种情况下云服务商有权先采取必要的变更、再通知租户;在何种情况下租户的自行变更需要备案、甚至要得到服务商的批准,以免影响到其他业务租户。
总结
结合前面三期对于IT项目不同阶段的讨论,我们实际上已经覆盖并形成了如下一个完整的生命周期。我将它们总结在下图中,以方便大家“挂图作战”。
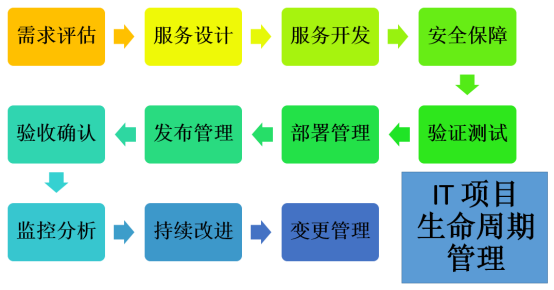
还记得一首老歌曾唱道:“人生豪迈,只不过是从头再来!”我们做项目的技术人员虽然可以如此,但是IT项目本身却像“开弓没有回头箭”那样,需要步步为营地扎实推进。
常言道“兵无常态,水无常势”。这些只是我从自己的经历和经验角度,进行的思考与总结,难免会由于能力限制了我的想象力。不过,我真诚地希望本系列中提到的各种有关IT项目的管理与治理实践,能够帮助您避免“踩坑”。千言万语汇成一句话:“Let’s have a happy ending!”
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】





