【51CTO.com原创稿件】数据,可谓是时下最炙手可热的东西。想当年,有“洛阳纸贵”的景象;看今朝,数据成为江湖大佬必争之物,火爆程度堪比“洛阳纸”。
而随着大数据浪潮来袭,大数据企业也如雨后春笋般不断涌出。几乎身边的每个人都在夸夸其谈大数据,仿佛大数据如“万金油”般,不仅为大企业所需,更可为小企业谋 “福利”。
然而,正当越来越多的企业加速涌入大数据洪流中时,却往往容易忽略——初创公司和大公司都宣称自己在收集大量数据:有的是TB级数据,有的数据量超过美国国会图书馆馆藏的所有信息,可是光靠数量往往建不起“数据护城河”。
首先,原始数据的价值与用来解决问题的数据没法相提并论。我们在公开市场上看到这一幕:充当数据聚合商和销售商的公司(比如Nielsen和Acxiom)其估值数,比开发数据和算法及机器学习支持的产品公司(比如Netflix或Facebook)低得多。

目前这一代人工智能初创公司已认识到这种差异,运用机器学习模型从自己收集的数据中获取价值。不过即使运用数据来支持基于机器学习的解决方案时,数据集的大小也只是一个方面。
一些应用要求将模型训练到准确性很高的程度,之后才能为客户提供价值,而另一些应用根本不需要什么数据;一些数据集是真正的专有数据,另一些数据集随时可以复制;一些数据的价值会慢慢衰减,另一些数据集则拥有持久的价值。
定义“数据需求”
机器学习应用可能需要数量大不相同的数据为最终用户提供有价值的功能。
MAP阈值
在云时代,最简可行产品(MVP)这个概念已深入人心:软件功能拥有足够的价值以寻求初始客户。在智能时代,我们同样看到数据和模型类似的一幕:证明采用很合理所需的***水平的准确智能,我们称之为***算法性能(MAP)。
大多数应用不需要***的准确性即可创造价值。比如说,面向医生的生产力工具可能最初简化将数据输入到电子健康记录系统的过程,但通过学习了解医生将数据输入到系统的方式,可以渐渐实现数据输入自动化。这种情况下MAP为零,因为单单基于软件功能,该应用一开始就有价值。然而,人工智能是产品核心的解决方案(比如通过CT扫描发现中风的工具)可能需要与现有(基于人的)解决方案相当的准确性。这种情况下,MAP就要有媲美放射科医生的表现,可能需要大量的数据,之后才可以投放市场。
性能阈值
并非每个问题都能以接近***的准确性来加以解决。鉴于当前的水平,一些问题太过复杂,无法完全建模。这种情况下,增加数据可能会逐渐提高模型的性能,但很快会出现边际效应递减的现象。
在另一个极端情况下,一些问题可以借助非常小的训练集,以接近***的准确性来加以解决,因为建模的问题相对简单,几乎没有维度需要跟踪,结果也没有太大的变化。
简而言之,有效解决问题所需要的数据量差别很大。我们将达到可行的准确性级别所需的训练数据量称为性能阈值。
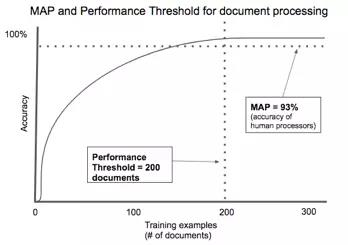
人工智能支持的合同处理是性能阈值低应用的一个典例。有成千上万种类型的合同,但大多数都有共同的主要方面:各有关方、交换的价值项目和时间范围等。像抵押贷款申请或租赁协议这些特定的文件高度标准化,以符合法规。我们在多家初创公司看到自动处理文件的算法只需要几百个示例来加以训练,就能达到可接受的准确度。
企业家需要小心权衡。如果性能阈值高,你会遇到启动问题:获取足够的数据来开发一款产品,推动客户使用、收集更多的数据;阈值太低了,你又无法建立起数据护城河!
稳定性阈值
机器学习模型拿从它们代表的实际环境获取的实例来训练。如果条件随着时间的推移而逐渐或突然变化,模型并没有随之变化,模型将会出现衰减。换句话说,模型的预测将不再可靠。
比如说,Constructor.io这家初创公司利用机器学习,对电子商务网站的搜索结果进行排名。系统观察客户点击搜索结果的情况,利用该数据来预测未来搜索结果的***顺序。但是电子商务产品目录在不断变化。如果模型对所有点击一视同仁,或者只拿某个时间段的数据集来训练,就有可能高估旧产品的价值,低估了新推出、目前流行的产品的价值。
保持模型稳定需要与环境变化同样的速度来采取新的训练数据。我们将这个数据采集速率称为稳定性阈值。
易过时的数据构建不了非常稳固的数据护城河。另一方面,如果稳定性阈值很低,长期访问丰富的新鲜数据可能成为一个很高的准入门槛。
找出长期可防御的机会
MAP、性能阈值和稳定性阈值是找出稳固数据护城河的几个核心要素。
先行者可能会有较低的MAP从而进入新的产品类别,但一旦他们创建了一个类别并成为***,未来参与者的门槛就不得低于先行者。
需要较少数据达到性能阈值,且保持这种性能(稳定性阈值)的领域其防御性不是很强。新进入者可以随时积累足够的数据,媲美或胜过你的解决方案。另一方面,一些公司利用低性能阈值(不需要太多数据)和低稳定性阈值(数据迅速衰减)来解决问题,它们仍可以通过比竞争对手更快地获取新数据来构建护城河。
稳固的数据护城河的更多要素
人工智能投资者往往通过“公共数据”与“专有数据”的热议,从而对数据集进行分类,但数据护城河的稳固性涉及更多方面,包括如下:
•可访问性。
•时间--积累数据、用于模型中的速度有多快?数据可以即时访问吗?还是要花大量的时间来获取和处理?
•成本--获取这些数据要花多少钱?数据用户是否需要为许可权付费,或者出钱请人来标记数据?
•独特性――类似数据是否广泛存在,可供别人随后建立模型,并获得同样的结果?这种所谓的专有数据称之为“商品化数据”可能更恰当――比如工作列表、随得可得的各类文档(比如保密协议或贷款申请)和人脸图像。
•维度――数据集描述了多少个不同的属性?其中许多属性是否与解决问题有关?
•广度――属性的值差异有多大?数据集是否考虑到个别情况和罕见的例外情况?能否从众多客户处汇集数据或学习结果,提供比仅仅来自一个客户的数据更广的覆盖范围?
•易腐性――一段时间后,该数据的适用范围有多广?用该数据训练的模型是否在长时间内具有持久性,还是说需要定期更新?
•良性循环――性能反馈或预测准确性之类的结果可以用作输入以改进算法吗?性能会随着时间的推移而提升吗?
***
软件定义的时代,正使得数据护城河对于打造长期竞争优势的公司来说比以往任何时候都来得重要。由于科技巨头们推广人工智能工具包以吸引云计算客户,数据集是提供差异化优势的最重要方式之一。真正有防御能力的数据护城河并不来自仅仅收集数量最多的数据,而是与某个特定的问题领域联系在一起,随着它为客户解决问题,独特、新颖的数据而越来越有价值。
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】
【编辑推荐】