今天企业、码农、风险资本、政府机构都伸长脖子望着人工智能。
这个人工智能机器学习领域已可开挖的黑金,千军万马挤独木桥的洪流,走向何处,他们真的知道吗?
如今媒体大V们随手甩出的“深度学习”的概念,不明觉厉的深度神经网络(DNN)、卷积神经网络(CNN)、深度置信网络(DBN)、卷积深度置信网络(CBDN),少有人知晓,它们都曾是无人问津的“屌丝”。
Yann Le Cun,一个需要被记住的名字
就像Leighton Stuart 因为被钦点、以及迎面而来的中国风名字“司徒雷登”,注定成为历史教材中政治幼稚的注脚。一个拼写有点汉味的法国人燕乐纯(Yann Le Cun),在人工智能领域,同样也会写进教材且成为“令人唏嘘”的代表。因为他绝对忘不了2012年这个有着诸多转折性事件的年份。
2012是神奇的,这一年,Hinton 教授和他的两个研究生 Alex Krizhevsky、 Illya Sutskever 将以卷积神经网络为基础的深度学习框架运用到 ImageNet 大型图像识别竞赛上,获得了空前的成功。
Hinton 教授就此在 AI 界封神。而将人工神经网络演进到深度学习,并且是卷积神经网络的第一个发明人和推广者燕乐纯,被遗忘在角落。
为什么说一次竞赛的胜利就成为了深度学习乃至 AI 的历史转折点?
因为 AI 能力的测试标杆,公认是在图像识别和处理:
1981年诺贝尔医学奖获得者 David Hubel 和 Torsten Wiesel 发现人的视觉系统的信息处理是分级的:从视网膜(Retina)出发,经过低级的V1区提取边缘特征,到V2区的基本形状或目标的局部,再到高层的整个目标(如判定为一张人脸),以及到更高层的PFC(前额叶皮层)进行分类判断等。高层的特征是低层特征的组合,从低层到高层的特征表达越来越抽象和概念化,也即越来越能表现语义或者意图。
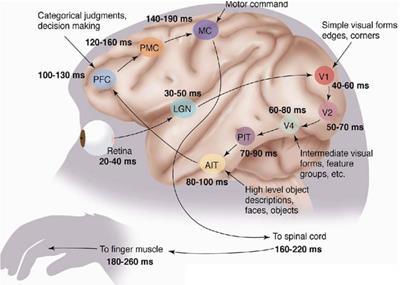
现在的深度神经网络,就是受此启发。
李飞飞点名推崇的重要人物 Jitendra Malik,这位伯克利教授, 把计算机视觉这个领域从图像处理带进了 AI。Jitendra 是最早一批看到了视觉本身在智能这个问题上的重要性——视觉是人类智能极其重要的部分。
但是 ImageNet 竞赛,这个继承了PASCAL VOC的人工智能图像识别的标杆,从2010年开始举办以来,深度学习并不是主流,而是另外一种机器学习办法——支持向量机(SVM)的天下。
ImageNet 就相当于机器学习的华山论剑,所以,什么武功最厉害?
- 2010年首次竞赛第一名团队,使用SVM方法构建的模型,识别分类的错误率为 28%。
- 2011年竞赛的冠军, 用类似SVM的Fisher Vector方法,构建模型的识别分类错误率为25.7%
- 而2012年竞赛,Hinton教授的团队,使用以卷积神经网络为基础的深度学习方案,他们训练的模型面对15万张测试图像时,预测的头五个类别的错误率只有 15.3%,而排名第二的日本团队,使用的SVM方法构建的模型,相应的错误率则高达 26.2%.
如此惊人的成绩,学术界轰动了。
更惊人的是,深度学习训练的模型(2012年之后就成为主流),在2015年的竞赛中部分类别图像的识别率上甚至超过了人类(虽然只占到所有图片分类中的千分一)。
然后就是我们众所周知的故事:2016年,以走棋网络和估值网络两个卷积神经网络为基础,结合了蒙特卡洛树搜索和强化学习两种方法开发的人工智能围棋程序AlphaGo,4:1 击败了围棋界的小李子——曾经的人类围棋第一人李世石,震惊世界。
在此之前,人们普遍认为,计算机最少还要20年才能击败人类顶尖高手,因为围棋是一种无法用计算机穷举击败人类的游戏,堪称人类智慧最后的殿堂。

2017年,AlphaGo的升级版本Master更是在网络快棋上大开杀戒,以60盘全胜的战绩挑落了所有排得上名号的人类围棋高手。让目前的围棋第一人柯洁产生了绝望感。
一个机器学习的小门派最终成为了江湖泰斗。众人只记住了Hinton教授,在 SVM 热潮中坚持研究神经网络,经历了20多年的门庭冷落,带领弟子练就了绝世武功。但是燕乐纯,则被称为神经网络辟荒的众大佬之一。实际上这哥们完全是跟Hinton教授一样,是“黑暗中举着火炬的人”。
人工神经网络的三次崛起和两次低谷
回顾历史,今天遍地开花的神经网络,并不是最近才冒出来的新鲜玩意,而是名副其实的老古董。
深度学习所依附的神经网络技术起源于上世纪50年代,那个时候还叫感知机(Perceptron)。在人工神经网络领域中,感知机也被指为单层的人工神经网络,尽管结构简单,却能够学习并解决相当复杂的问题。
虽然最初被认为有着良好的发展潜能,但感知机最终被证明存在着严重的不可逾越的问题:它只能学习线性可分函数。连简单的异或(XOR映射)等线性不可分问题,都无能为力。
1969年,Marvin Minsky出版的《Perceptrons》书,是一个历史的转折点,神经网络第一次被打倒。Minsky的书最著名的观点有几个:
(1)单层感知机没用,我们需要用MLPs(多层感知机,多层神经网络的另一种说法)来代表简单的非线性函数,比如XOR (异或)映射;
(2)世界上没人有办法将MLPs训练得够好。
简而言之,要解决感知机(单层神经网络)学习线性不可分函数的问题,就必须发展多层感知机,即中间包含一个隐层的两层神经网络。
但是当时,根本找不到运用在多层神经网络上的有效算法。学术权威开启了神经网络的反右运动,悲观主义开始蔓延。
从现在看,突破性的误差反向传播算法,即著名的BP算法,开启训练多层神经网络的“钥匙”,其实那个时候已经存在了。
冰冻十年中,尽管Paul Werbos在1974年的博士毕业论文中深刻分析了将BP算法运用于神经网络方面的可能性,成为美国第一位提出可以将其用于神经网络的研究人员,但是他没有发表将BP算法用于神经网络这方面的研究。因为这个圈子大体已经失去解决那些问题的信念。
这时候我们的燕乐纯燕大侠上场了。80年代博士在学期间,他提出了神经网络的反向传播算法原型(当时他在Hinton的实验室做博士后研究,Hinton是燕乐纯的导师)。
众人只知道,1986年BP算法开始流行开来,是因为Rumelhart、Hinton、Williams合著的《Learning representations by back-propagating errors》,真正的,David Parker 和燕乐纯是事先发现这一研究进路的两人。
1989年,燕大侠加入贝尔实验室,他开始将1974年提出的标准反向传播算法应用于深度神经网络,这一网络被用于手写邮政编码识别,尽管因为种种问题失败。但是这一时期,燕大侠发明了真正可用的卷积神经网络。
到90年代中期,贝尔实验室商业化了一批基于卷积神经网络的系统,用于识别银行支票(印刷版和手写版均可识别)。直到90年代末,其中一个系统识别了全美国大概10%到20%的支票。
燕大侠和其他人发展的神经网络,正开始被热捧的时候,他一生较劲的对象Vapnik(贝尔实验室的同事)出现了。因为两层神经网络尽管解决了10年前困扰神经网络界的线性不可分问题,但是多层神经网络在实际发展中碰上了新的难题:
- 1.尽管使用了BP算法,一次神经网络的训练仍然耗时太久,因为当时没有如今可以用于大规模并行计算的GPU。比如,燕大侠最早做的手写邮政编码识别系统,神经网路的训练时间达到了3天,无法投入实际使用。
- 2.训练优化存在局部最优解问题,即过拟合,也许这是机器学习的核心难题。简要来说,过度拟合指的是对训练数据有着过于好的识别效果,这时导至模型非常复杂。这样的结果会导致对训练数据有非常好的识别较果,而对真实样本的识别效果非常差。
- 3.随着添加越来越多的隐含层,反向传播传递给较低层的信息会越来越少。即著名的梯度消失问题。由于信息向前反馈,不同层次间的梯度开始消失,对网络中权重的影响也会变小,因而隐藏层的节点数需要调参,这使得使用不太方便,训练的模型质量并不理想。
90年代中期,由Vapnik等人发明的支持向量机(Support Vector Machines,SVM)诞生,它同样解决了线性不可分问题,但是对比神经网络有全方位优势:
1、高效,可以快速训练;2、无需调参,没有梯度消失问题;3、高效泛化,全局最优解,不存在过拟合问题。
几乎全方位的碾压。
SVM 迅速打败多层神经网络成为主流。后来一度发展到,只要你的论文中包含神经网络相关的字眼,非常容易拒稿,学术界那时对神经网络的态度可想而知。
这个事情连如今的谷歌老大都记得。2017年年初,谢尔盖在达沃斯的一个对谈环节上还回忆说,
“坦诚来说,我根本没关注人工智能”,“90 年代学习计算机科学的人都知道,人工智能并不管用,人们尝试过,他们试过各种神经网络,没有一个管用。”
神经网络再次堕入黑暗。10年沉寂中,只有几个学者仍然在坚持研究。比如一再提及的Hinton教授。
2006年,Hinton在《Science》和相关期刊上发表了论文,首次提出了“深度置信网络”的概念。与传统的训练方式不同,深度信念网络有一个“预训练”(pre-training)的过程,它的作用是让神经网络权值找到一个接近最优解的值,之后再使用“微调”(fine-tuning)技术,即使用反向传播算法或者其他算法作为调优的手段,来对整个网络进行优化训练。这两个技术的运用大幅度提升了模型的性能,而且减少了训练多层神经网络的时间。他给多层神经网络相关的学习方法赋予了一个新名词——“深度学习”。
后面的故事我们都知道了,2012年Hinton的团队用燕乐纯赖以成名的卷积神经网络,和自己在深度置信网络的调优技术,碾压了其他机器学习办法。
至此,深度学习开始垄断人工智能的新闻报道,像Hinton、燕乐存和他们的学生摇滚明星一般受到追捧,惯于见风使舵的学者们也来了个180度大转变,现在是没有和深度学习沾上边的文章很难发表了。
除了名,还有利,谷歌、Facebook、Twitter们不但把学术界人物挖了个遍,更是重金收购深度学习大佬们所创建的公司,坐了几十年冷板凳的人忽然一夜之间身价暴涨财务自由。
令人唏嘘的是,现在主导Facebook AI 实验室的燕乐纯,他不断呼吁学术界对深度学习保持冷静,批判深度学习的泡沫繁荣...
深度神经网络“高效”和“搞笑”并存
嗯,深度学习变得如此有用,人工智能正在蓬勃发展,很多人甚至开始谈论人类社会“技术奇点”的到来...
下棋、图像识别、自动驾驶、金融分析师...看似无所不能、比进化了数百万年人类更有“智慧”的人工神经网络,却有人发现,它有一些比较“搞笑”的方面:
比如 Jeff Clune、Anh Nguyen、Jason Yosinski 训练了一个用于识别物体的系统,该系统99.6%确信左图是一只海星,同样99.6%确信右图是只猎豹。

而另一个来自Google、Facebook、纽约大学和蒙特利尔大学研究人员组成的团队,开发的一个神经网络系统,认为左图是一只狗,而右图(仅在左图的基础上略微改变了像素)是一只鸵鸟。

比较诡异的是,这种事情不是发生了一次两次,而是稳定地出现。
“一个为某一模型生成的样本,通常也会被其他模型错误归类,即使它们有着完全不同的架构。”
“即使使用的是完全不同的数据集。”

左图被神经网络判定为熊猫。给它人为叠加上中图所示微小的扰动(实际叠加权重只有0.7%),就获得了右图。在人类看来,左图和右图没有区别;可是AI却会以99.3%的置信度,一口咬定右图是一只长臂猿。
这些“错误”,不知道是神经网络的缺陷,还是人类肉眼凡胎不识“真相”,目前这些错误被取了一个名字——“对抗样本”。
结尾
梳理人工神经网络的历史,感知机—双层神经网络—多层神经网络—深度学习,我们明显可以看到这是怎样一个曲折的轨迹。
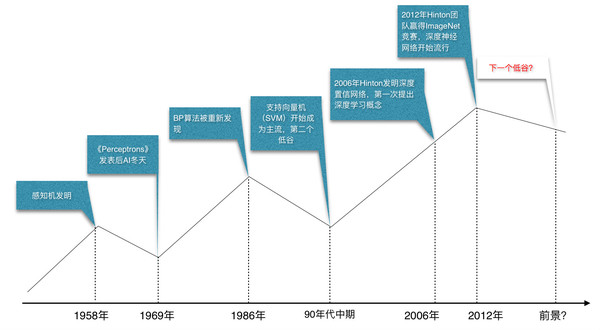
过去神经网络曾经被人弃之如敝履,未来就一定不会遭遇下一个低谷?我想,没人敢打包票。
无论是目前过拟合、梯度消失的固疾,还是对抗样本的问题,都说明以神经网络为代表的机器学习目前还是非常“弱”的人工智能。
而且有一家与DeepMind齐名的人工智能公司 Vicrious ——吸引了Mark Zuckerberg、Elon Musk、Peter Thiel、Jeff Bezos 私人投资,专注于通用人工智能的另类,他们的创始人 Scott Phoenix 曾说:
深度神经网络(DNN)需要大量的训练数据,不能很好地适用于新的任务或环境。
(注:有变数,最近DeepMind最近新论文,他们宣称发明弹性权重巩固算法让 AI 拥有“记忆”,目前只能胜任特定领域一项任务的神经网络,开始能够习得“多项技能”)
深度学习往往侧重于学习输入感知与输出动作之间的映射(如用于做分类决策或者是围棋、Atari游戏上的移动的决策),对大脑功能的模拟,太过单一。
智能的本质是能够学习一个所处在世界的心理模型(mental model ),然后能否在这个模型上进行模拟(所谓想象力)。
深度学习是一个黑盒,我们设定了规则、输入了数据、训练出一个数据处理模型,但是并不了解数据处理在内部究竟如何进行。
那些在输入层、隐层、目标层之间连接的人工神经元发生的所有事情,目前根本无法知晓,所以也无法预测输出的结果:“我们看着Master走出了惊世骇俗的落子,看着它表演,它却不能告诉我们为什么要走这里。”
深度学习用大量的数据样本才能训练“泛化能力”,相比李世石,后者才是真正的天才——他用远远少于AlphaGo的训练样本,达到了接近AlphaGo的水平。
目前,人工神经网络仅仅是模拟大脑皮层的一小部分运行方式,而且是跨过了“认识世界”、“认识智能的本质” 这个阶段,直接到了“改变世界”。
基础理论并不成熟的工程应用,其实有着极大的隐患。